Code
source("R/table_with_options.R")source("R/table_with_options.R")We are starting our first exploratory data analysis around ISPs in the FCC NBM data set. It should be kept in mind that an ISP can be listed multiple times at the same location (offering multiple service).
Our goal is being able to take FCC data and 1. correctly identify the single ISP that is providing each reported service (i.e., deduplication of ISP names) 2. correctly identify that ISP over time (from the same program and from other FCC products).
How should we define an ISP? How can we define coverage (should a service 0/0 be considered as part of the extent of an ISP’s coverage)?
We shifted a bit from exploring to trying to classify the quality of information we have from FCC about ISP.
The query that generated the data set is here:
select
frn,
provider_id,
brand_name,
count(distinct location_id) as cnt_locations,
count(*) as cnt_locations_services,
bool_or(case when technology = 10 then true else false end) as has_copperwire,
bool_or(case when technology = 40 then true else false end) as has_coaxial_cable,
bool_or(case when technology = 50 then true else false end) as has_fiber,
bool_or(case when technology >= 70 then true else false end) as has_wireless,
bool_or(case when technology = 60 or technology = 61 then true else false end) as has_satel,
array_agg(distinct state_abbr)
from staging.june23
group by frn, provider_id, brand_nameThe name of the columns match the FCC’s documented descriptions.
We are adding:
cnt_locations_services: count of services, in one location you can have multiple services with different providers, technology and speeds provides (sometimes one providers can have multiple technology and/or multiple speeds)
cnt_locations: count of locations covered by this specific set of brand_name, provider_id, state_abbr and technology (here if a provider declare providing different speed in that location it will not be counted)
a serie of flag (has) telling if this “combo” is proving said technology
an array listing in which states are present our “combo”
We have from FCC:
Source: https://us-fcc.app.box.com/v/bdc-data-downloads-output page 4
frn FCC Registration Number; “number of the entity that submited the data”. It is supposed to be a string of 10 characters (with padding 0).
provider_id: “unique identifier for the fixed service provider”
brand_name: “Name of the entity or service advertised or offered to consumers.”
Every row is matching a combination of unique FRN, Provider ID and brand name.
get_me_isp <- function(path) {
isp <- read.csv(path,
colClasses = c(frn ="character",
provider_id = "character",
brand_name = "character",
cnt_locations = "character",
cnt_locations_services = "character",
has_copperwire = "logical",
has_coaxial_cable = "logical",
has_fiber = "logical",
has_wireless = "logical",
has_satel = "logical",
array_agg = "character"))
isp[["cnt_locations"]] <- as.numeric(isp[["cnt_locations"]])
isp[["cnt_locations_services"]] <- as.numeric(isp[["cnt_locations_services"]])
return(isp)
}
isp <- get_me_isp("data/isp.csv")table_with_options(isp)Number of unique frn: 2879
Number of unique provider_id: 2184
Number of unique brand name pre cleaning: 2902
count_and_clean <- function(vec) {
length(unique(tolower(trimws(gsub("_", " ", vec)))))}
num_brand_name <- count_and_clean(isp[["brand_name"]])Removing all capitalization and change underscore for white space help lower the number of unique brand names to: 2878
isp[["clean_name"]] <- tolower(trimws(gsub("_", " ", isp[["brand_name"]]))) FRN can be wrong or not meaningfullprovider_id can be wrongOne case:
| frn | provider_id | brand_name | cnt_locations | cnt_locations_services | has_copperwire | has_coaxial_cable | has_fiber | has_wireless | has_satel | array_agg | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0003738655 | 130432 | “EATEL Corp.” | 83537 | 86548 | true | true | true | false | false | {LA} | ||
| 0009873712 | 131103 | “EATEL Corp.” | 34494 | 34497 | false | true | true | false | false | {LA} |
Other case:
| frn | provider_id | brand_name | cnt_locations | cnt_locations_services | has_copperwire | has_coaxial_cable | has_fiber | has_wireless | has_satel | array_agg | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0002626984 | 130008 | Acentek | 47 | 47 | true | false | true | false | false | {MN} | ||
| 0002626984 | 130008 | ACENTEK | 1395 | 1395 | true | false | false | false | false | {MN} | ||
| 0002645927 | 130008 | Acentek | 19521 | 26636 | true | false | true | true | false | {IA,MN} |
isp[["few_locations"]] <- NA_integer_
for (i in 1:10) {
isp[isp[["cnt_locations"]] == i, "few_locations"] <- i
}
#feel bad relying on table removing NA
few_loc <- as.data.frame(table(isp$few_locations))
names(few_loc) <- c("Number of locations", "Number of cases")
knitr::kable(few_loc)| Number of locations | Number of cases |
|---|---|
| 1 | 43 |
| 2 | 9 |
| 3 | 12 |
| 4 | 5 |
| 5 | 2 |
| 6 | 4 |
| 7 | 8 |
| 8 | 5 |
| 9 | 3 |
| 10 | 3 |
Potential solutions:
We can decide to not keep those rows
Merge them with either other rows that is matching provider_id or frn (when this is an option)
temp <- sapply(split(isp$frn, isp$provider_id), function(x) length(unique(x)))
dta <- data.frame(provider_id = names(temp), frn_by_provider_id = temp)
# correct lower/upper case / replace underscore by " " / some white space on both side
# triming whispace did not improve for this dataset but I should keept doing it
dta[["unique_brand_name_by_provider_id"]] <- sapply(split(isp$brand_name, isp$provider_id),
count_and_clean)
dta[["same_state_by_provider_id"]] <- sapply(split(isp$array_agg, isp$provider_id), function(x) length(unique(x)))
isp <- merge(isp, dta, by.x = "provider_id", by.y = "provider_id",
all.x = TRUE, all.y = TRUE)
more_frn_than_provider <- subset(isp, isp$frn_by_provider_id > 1)
table_with_options(more_frn_than_provider)Unique provider_id + brand_name are kind of “green” (for one time frame):
Number of green isp: 1972
We can have one provider_id with multiple frn and same or not brand_name (see TSC for example / 150266)
It seems:
Windstream has 37 different frn: we can maybe test if it has windstream in it’s name ..
Otelco/GoNet (18 cases)
Rally Networks/Oregon Telephone Company, is their frn wrongs ? (17 cases)
Same Provider for differents frn and brand_name in Minesota (MN) (16 cases)
160127 I do not see any kind of specific pattern for this one
131486 seems to be RiverStreet Networks with various frn (13 cases) -> will be catch by unique_brand_name_by_provider_id
190233 multiple brand name and frn but seems to be in Texas and Oklahoma (13)
131226 seems to be Fastwyre Broadband divided by technology and states (12 cases) -> will be catch by unique_brand_name_by_provider_id
130804 seems to be Mediacom (+ Bolt) with different states and names indicating their states (11 cases)
Google Fiber (240041) seems to be have frn split by states (with a weird ‘Webpass, Inc.’) (11 cases) -> will be catch by unique_brand_name_by_provider_id (except Webpass, Inc which is weird, technology is 70 that I should correct)
AT&T Inc (130077) multiple frn (10 cases) -> filter by unique_brand_name_by_provider_id
130079 = Astound_Broadband (10 cases) -> will be catch by unique_brand_name_by_provider_id
Verizon -> filter by unique_brand_name_by_provider_id
long ling (130757 ) & co are problematics (multiples names / one provider / 3 states )
130906 is also hard to fix
Assuming that same name (clean version) + same provider_id provide us with a unique ISP, it helps move to greensih:
table_with_options(more_frn_than_provider[more_frn_than_provider$unique_brand_name_by_provider_id == 1,])This is removing 194 out of 1170.
Not too sure about this one.
This is the case for “EATEL”.
temp <- sapply(split(isp$provider_id, isp$clean_name),
function(x) length(unique(x)))
dta <- data.frame(clean_name = names(temp), provider_id_by_clean_name = temp)
isp <- merge(isp, dta, by.x = "clean_name", by.y = "clean_name",
all.x = TRUE, all.y = TRUE)
provider_id_by_clean_name <- subset(isp, isp$provider_id_by_clean_name > 1)
table_with_options(provider_id_by_clean_name)This could also move 63 cases in the greenish spot. -> nop
# if it has unique brand name and frn by provider id id should be good
temp <- isp$frn_by_provider_id + isp$unique_brand_name_by_provider_id
isp[["rdy_to_go"]] <- ifelse(temp == 2, "green", "not green")
# cases where we have a unique frn and provider id but not unique brand name
# default of olive is that we need to pick a name out of more than one
temp <- ifelse(isp$frn_by_provider_id == 1, 1, 0) + ifelse(isp$unique_brand_name_by_provider_id > 1, 1, 0)
isp[temp == 2, "rdy_to_go"] <- "olive"
# the few locations should be "red" and maybe dropped later
isp[which(isp$few_locations == "few locations"), "rdy_to_go"] <- "red"
table_with_options(isp)A good example could be 131167 and how we can discriminate Orbitel communications. We can also prob. raise the bar of “few locations”.
A quick summary of where we are:
table(isp[["rdy_to_go"]])
green not green olive
1778 1170 222 The data was generated from June 23 FCC release and assumed that an FRN = ISP.
Can we guess who is a small ISP?
# con <- cori.db::connect_to_db("proj_calix")
# bob <- DBI::dbReadTable(con, "frn_desc")
# DBI::dbDisconnect(con)
# bob[["is_calix"]] <- NULL
# write.csv(bob, "data/frn_desc.csv")
frn_desc <- read.csv("data/frn_desc.csv")
#classInt::classIntervals(cnt_locations, n = 20, style = "jenks")
# not that great
table_with_options(frn_desc)cnt_locations <- frn_desc[["cnt_locations"]]
summary(cnt_locations) Min. 1st Qu. Median Mean 3rd Qu. Max.
1 1384 5476 253046 19588 114863490 boxplot(cnt_locations, horizontal = TRUE, col = 2, border = 2, frame = F, main = "Count of locations per ISP") 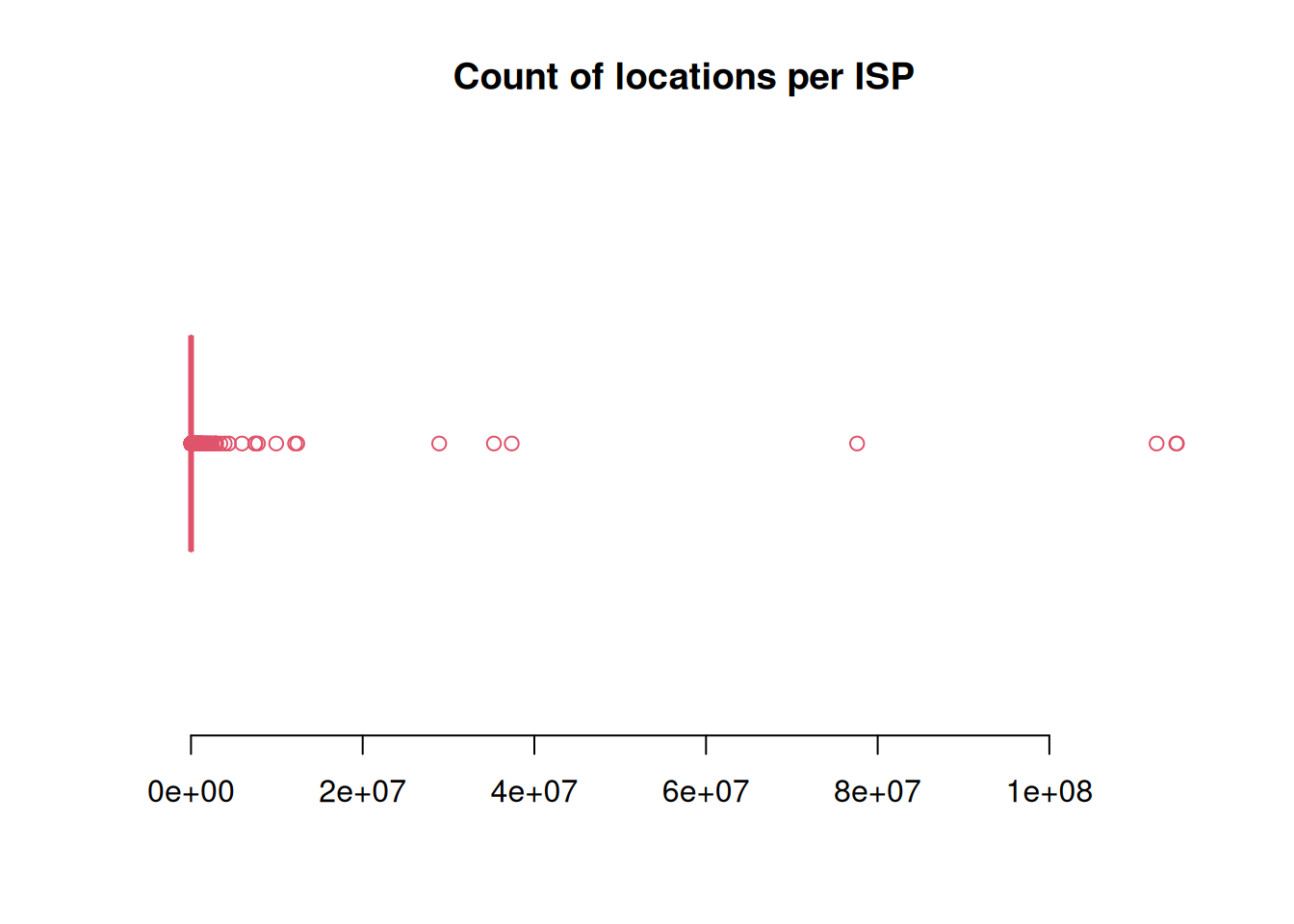
Some ISP are declaraing covering a huge number of locations. Some low counts are probably errors.
Count of FRN with a less than 10 locations: 36
Count of FRN with more than 500 000 locations: 74
frn_desc$n_states <- lengths(strsplit(gsub("\\{|\\}", "", frn_desc$states), ","))If we filter them out (removing 110 cases):
location_filter <- 100000
frn <- frn_desc[frn_desc$cnt_locations >= 10 & frn_desc$cnt_locations <= location_filter ,]
# dim(frn_desc)
# dim(frn)
hist(frn$cnt_locations, col = 2,
main = sprintf("Less than %s", location_filter), xlab = "count locations")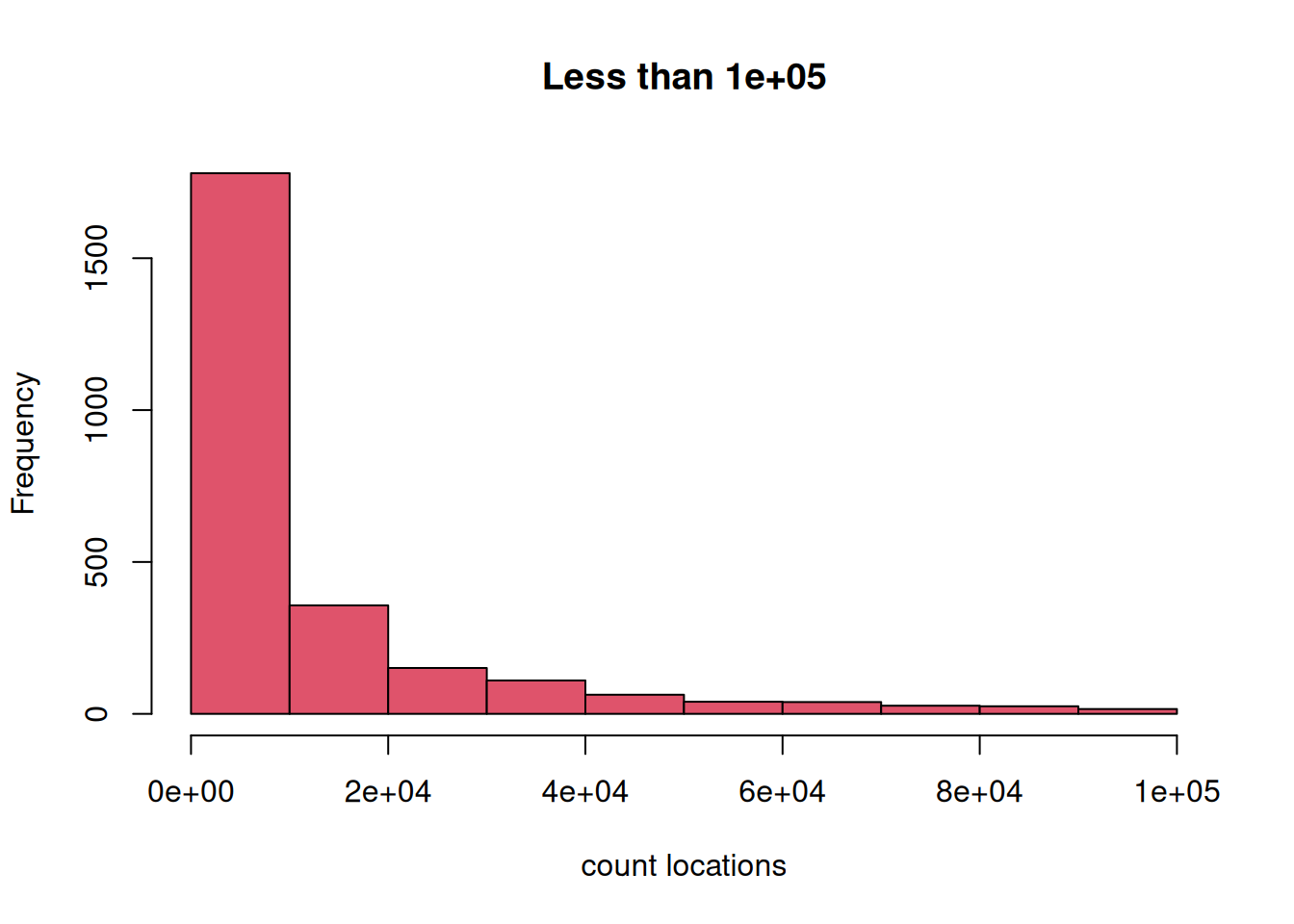
location_filter <- 10000
frn <- frn_desc[frn_desc$cnt_locations >= 10 & frn_desc$cnt_locations <= location_filter ,]
# dim(frn_desc)
# dim(frn)
hist(frn$cnt_locations, col = 2,
main = sprintf("Less than %s", location_filter), xlab = "count locations")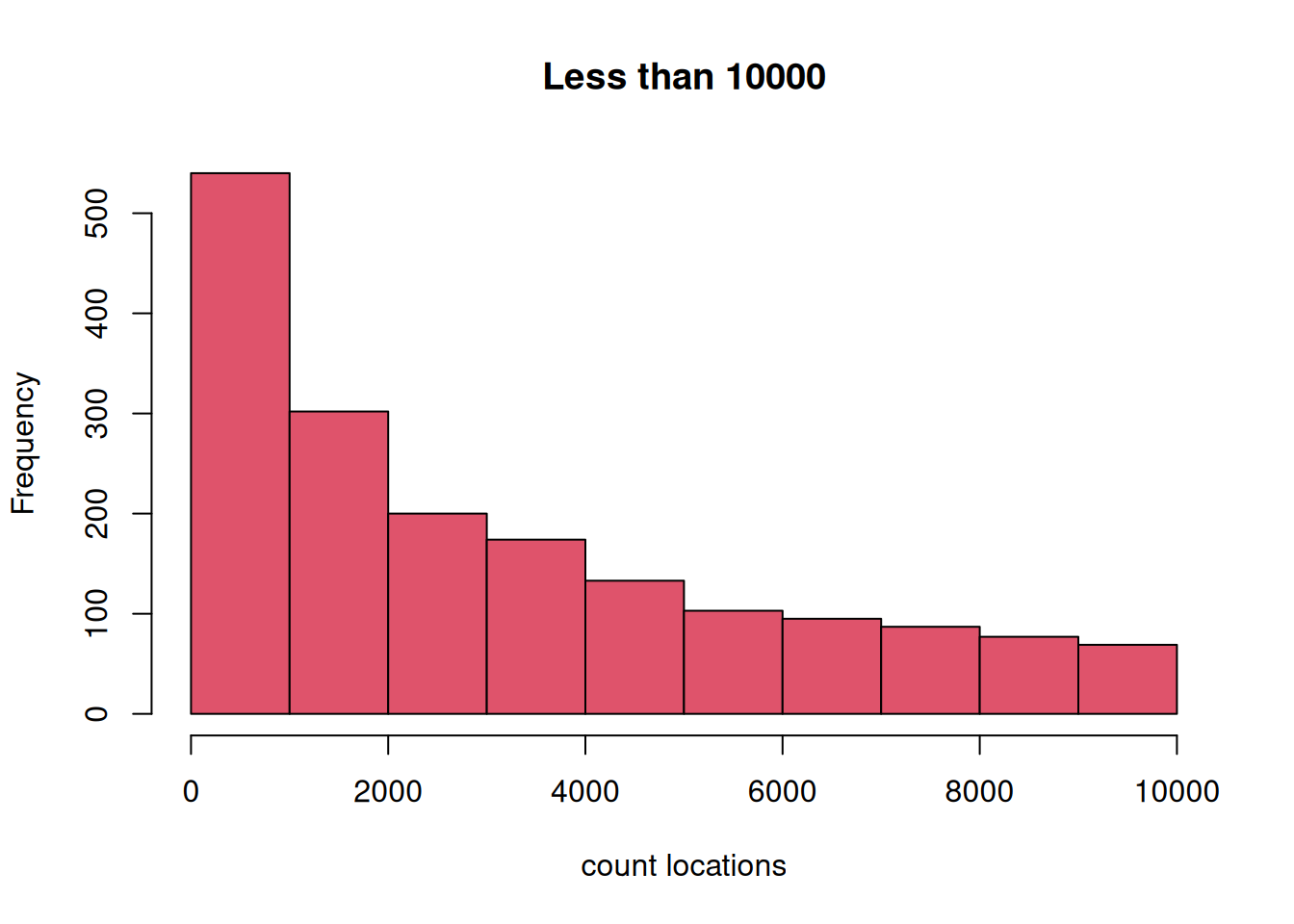
List of ISP that the Broadband team that are good reference of small provider:
| Name | FRN | Locations |
|---|---|---|
| Newport Utilities, TN | 0027152438 | 15383 |
| SandyNet, OR | 0004119376 | 4439 |
| ECFiber, VT | 0027379676 | 22926 |
| Maple Broadband, VT | 0032366692 | 315 |
| Uplink | 0026218602 | 1611 |
| Black Bear Fiber | 0025132648 | 1583 |
| QCOL | 0019663095 | 5610 |
| Salsgiver | 0011167079 | 29941 |
| All Points Broadband | 0023524705 | 107803 |
| Marquette-Adams Telephone co-op | 0003774023 | 130783 |
| USI fiber | 0017096538 | 71466 |
| Scott county telephone co | 0002069862 | 7829 |
| PANGAEA | 0016202236 | 8410 |
| Blue Mountain Networks | 0005450507 | 310013 |
Side notes:
Newport Utilities = NUconnect
SandyNet, OR = City of Sandy, OR
USI FIber =
Blue Mountain Networks = Blue Ridge Mountain Electric Membership Corporation